这次的安全漏洞真的是给微架构界狠狠一耳光……
长年以来通用处理器的竞赛都集中在性能上,为了性能可以做很多冒险的行为(例如分支预测、投机执行)。而相关研究也都集中在保障处理器运行结果的正确性上,比如 precise interrupt,复杂的内存 replay 机制,缓存一致性研究等等,在安全方面的关注比较弱,设计时也无暇顾及这类问题,因而导致了这次的悲剧
这次的安全漏洞算是 “旁敲侧击” 猥琐信息盗窃的典型,类似的手法在虚拟化攻击中早就有讨论过。例如同一台物理机器跑多个机器实例,客户 A 可以通过一些内存序列借用处理器的缓存机制嗅探客户 B 内存的数据,因此不少云服务商在那之后开始 “浮动” 分配机器,避免让两台客户机在同一台物理机上共存太久以缓解这类攻击。
不过这次的攻击更猥琐,影响也更严重,主要是因为没有很好的软件手段能在低性能折损的前提下修复这个问题。而在硬件层如何彻底避免这类信息泄露也不简单,想必这会成为处理器设计厂商和研究机构的下一个热门课题。
背景知识:
当代处理器微架构的性能优化主要体现在三个方面:流水线、缓存、并行度。其中流水线在 20 年前就已经广泛使用,但是缓存和并行度上面可挖掘的东西更多一些,近年仍旧在继续优化。
两者中缓存主要是为了解决冯诺依曼机的缺陷,即数据要搬运到处理单元执行。大的储存器慢,快的储存器小,因此当代处理器都使用了多级缓存来缓解这个问题——提前将数据搬运到小而快的储存器上,到用的时候就不用等待了。为此处理器甚至会进行更激进的预取(AMD Ryzen 性能提升五个独门绝技之一就是预取器的改进)
并行度可挖掘的就更多,除了多线程外单线程也尽量拆分成可以并行执行的指令区段执行,这也被称为 “指令并行度”(ILP)
总的而言这次的攻击就使用了处理器微架构在并行度和缓存的优化:
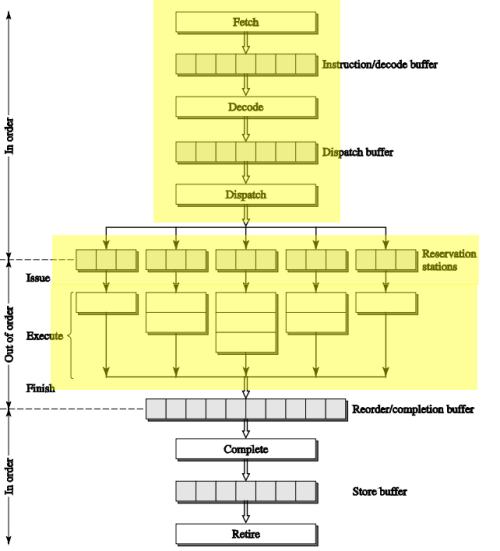
乱序执行是提高指令并行度的基础手段之一,例如下面有一个指令序列
1:ld R1, addr_1
2:ld R2, addr_2
3:st R2, addr_3
其中第一条指令将地址 1 读到寄存器 1,第二条指令将地址 2 读取到寄存器 2,第三条指令则将寄存器 2 的数据储存到地址 3。
在这里,指令 3 依存于指令 2 的完成,而指令 1 和指令 2、3 无关
传统的顺序执行即按 1,2,3 的顺序执行,假设 addr_1 是内核地址,用户态下尝试读取就会报错,后续指令也不会执行
但是在乱序执行中由于指令 2、3 和指令 1 没有依存关系,如果指令 1 阻塞了,那么指令 2 和 3 仍旧可以执行以充分利用执行单元。
在更激进的处理器设计中,就算指令 2 依存于指令 1 的完成,处理器仍旧会 “投机执行”,提前将后续指令需要的数据搬运到缓存。这个设计在当代处理器中不少见,苹果不久前 2 亿美元的官司正是围绕着相关的投机读写预测专利展开的
当然出于正确性考虑,在指令提交的时候仍旧得按顺序走,也就是虽然 2 和 3 可能先执行,但是他们仍旧要等待 1 提交后才能提交,如果 1 出错了(例如用户态非法访问内核态),那么 2 和 3 的结果也会被清除。这个清除流程很复杂,一般来说性能损失也非常大,所以是清得越少越好。
一般而言设计者都尽量保证寄存器能恢复,但缓存就无所谓了,因为从处理器核心的抽象层来看,缓存和内存是一体的,没有区别,唯一的区别就是存取时间的不同。
攻击原理:
然而正是这个存取时间的差异给攻击者带来了可乘之机:假设访问一个内存地址,缓存命中的时候只需要 3 个时钟周期,而缓存失误的时候需要 400 个时钟周期,我们可以构造一个这样的程序来进行嗅探:
1:读取一个内核地址的数据
2:将内核地址读出来的数据 AND 1
3:读取(用户地址 + 指令 2 的结果)这个地址
背景知识:缓存以 “行” 来划分,一般一行缓存有 8 个 64-bit 的 word,当然具体到不同设计可能不一样。
可以构造一个地址落在缓存行的末尾,当其加 0 时是在缓存行 1,加 1 时是缓存行 2
在攻击前,先用特殊指令将这两行缓存从处理器的缓存中清除掉,然后构造一个精巧的程序,这个程序需要让指令 2 和 3 先于指令 1 来执行(例如可以用其他指令增加指令 1 的 dependency 来阻挡其执行进程)。此时处理器就会优先调度指令 2 和 3 执行,如果内核态的数值是 0,则处理器会预读缓存行 0,如果内核态的数值是 1,则处理器会预读缓存行 1。
最终,处理器会执行指令 1 并抛出异常,但指令 2 和 3 对应的访问会残留在缓存里。
黑客只需要在其后访问这两个缓存行,计算延迟,就可以得知处理器到底预读了哪一行缓存,最终得以反推出内核地址中的数据是多少。
这种清空缓存行后重读的攻击技巧不少见,但如此细化到处理器微结构的层级上就不常见了。
我个人觉得这对于当前微架构界的冲击不小,不少学界提高性能的优化都经不起这个攻击的考验……
投机执行是所有当代处理器的性能基石,我相信就算早先披露的 meltdown attack 仅针对 Intel 处理器,这类攻击完全可以泛化后通过处理器其他微状态构造新的 side channel 攻击。因此我估计 AMD、ARM 的高性能产品也将无法幸免。
文章来源:https://bbs.kafan.cn/thread-2112818-1-1.html